|
|
1. ps-lite
ps-lite是参数服务器(ps)的一种轻量实现,用于构建高可用分布式的机器学习应用。通常是多个节点运行在多台物理机器上用于处理机器学习问题,一般包含一个schedule节点和若干个worker/server节点。
ps-lite的三种节点:
- Worker:负责主要的计算工作,如读取数据,数据预处理,梯度计算等。它通过push和pull的方式和server节点进行通信。例如,worker节点push计算得到的梯度到server,或者从server节点pull最新的参数。
- Server:用于维护和更新模型权重。每个server节点维护部分模型信息。
- Scheduler:用于监听其他节点的存活状态。也负责发送控制命令(比如Server和Worker的连接通信),并且收集其它节点的工作进度。
ps-lite 支持同步和异步两种机制
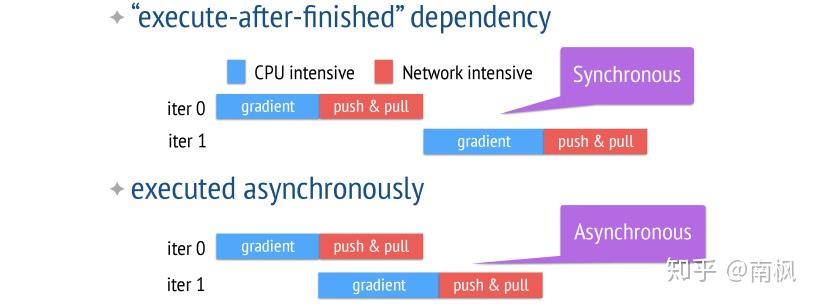
- 在同步的机制下,系统运行的时间是由最慢的worker节点与通信时间决定的
- 在异步的机制下,每个worker不用等待其它workers完成再运行下一次迭代。这样可以提高效率,但从迭代次数的角度来看,会减慢收敛的速度。
ps-lite常应用于推荐系统中的ctr预测中,用以解决数据量较大,特征较多的问题,同时也有很多开发者贡献自己的应用源码。本文就结合基于ps-lite实现的分布式lr为例,记录一下ps-lite的具体使用,代码放在了:
在 https://github.com/xswang/xflow 的基础上修改的[1] 2. 代码实例
接下来就以分布式LR为例,简单介绍一下代码的各部分功能:
主函数:
int main(int argc, char *argv[]) {
if (ps::IsScheduler()) {
std::cout << &#34;start scheduler&#34; << std::endl;
}
if (ps::IsServer()) {
std::cout << &#34;start server&#34; << std::endl;
xflow::Server* server = new xflow::Server();
}
ps::Start();
if (ps::IsWorker()) {
std::cout << &#34;start worker&#34; << std::endl;
int epochs = std::atoi(argv[4]);
if (*(argv[3]) == &#39;0&#39;) {
std::cout << &#34;start LR &#34; << std::endl;
xflow::LRWorker* lr_worker = new xflow::LRWorker(argv[1], argv[2]);
lr_worker->epochs = epochs;
lr_worker->train();
}
if (*(argv[3]) == &#39;1&#39;) {
std::cout << &#34;start FM &#34; << std::endl;
xflow::FMWorker* fm_worker = new xflow::FMWorker(argv[1], argv[2]);
fm_worker->epochs = epochs;
fm_worker->train();
}
if (*(argv[3]) == &#39;2&#39;) {
std::cout<< &#34;start MVM &#34; << std::endl;
xflow::MVMWorker* mvm_worker = new xflow::MVMWorker(argv[1], argv[2]);
mvm_worker->epochs = epochs;
mvm_worker->train();
}
}
ps::Finalize();
}
- 对于 Scheduler 节点,直接调用ps-lite的Start()和Finalize()启动和准备回收;
- 对于 Server 节点,可以定义一个单独的Server类;
- 对于 Worker 节点,对于不同的模型方法定义对应的处理类,例如:xflow::LRWorker;
2.1 Scheduler 节点
对于scheduler节点进行初始化,Scheduler机器对应的IP地址设定为$DMLC_PS_ROOT_URI
2.2 Server 节点
Server类的定义:
namespace xflow {
class Server {
public:
Server() {
server_w_ = new ps::KVServer<float>(0);
server_w_->set_request_handle(SGD::KVServerSGDHandle_w());
//server_w_->set_request_handle(FTRL::KVServerFTRLHandle_w());
server_v_ = new ps::KVServer<float>(1);
//server_v_->set_request_handle(FTRL::KVServerFTRLHandle_v());
server_v_->set_request_handle(SGD::KVServerSGDHandle_v());
std::cout << &#34;init server success &#34; << std::endl;
}
~Server() {}
ps::KVServer<float>* server_w_;
ps::KVServer<float>* server_v_;
};
} // namespace xflow
#endif // SRC_MODEL_SERVER_H_
其中定义了两个KVServer类型的权值: server_w_、server_v_对应模型的w和b,然后将在request handler中定义优化策略,这部分是server的核心处理逻辑,以SGD为例:
typedef struct SGDEntry_w {
SGDEntry_w(int k = w_dim) {
w.resize(k, 0.0);
}
std::vector<float> w;
} sgdentry_w;
struct KVServerSGDHandle_w {
void operator()(const ps::KVMeta& req_meta,
const ps::KVPairs<float>& req_data,
ps::KVServer<float>* server) {
size_t keys_size = req_data.keys.size();
size_t vals_size = req_data.vals.size();
ps::KVPairs<float> res;
if (req_meta.push) {
w_dim = vals_size / keys_size;
CHECK_EQ(keys_size, vals_size / w_dim);
} else {
res.keys = req_data.keys;
res.vals.resize(keys_size * w_dim);
}
for (size_t i = 0; i < keys_size; ++i) {
ps::Key key = req_data.keys;
SGDEntry_w& val = store[key];
for (int j = 0; j < w_dim; ++j) {
if (req_meta.push) {
float g = req_data.vals[i * w_dim + j];
val.w[j] -= learning_rate * g;
} else {
for (int j = 0; j < w_dim; ++j) {
res.vals[i * w_dim + j] = val.w[j];
}
}
}
}
server->Response(req_meta, res);
}
private:
std::unordered_map<ps::Key, sgdentry_w> store;
};
- 对于push操作,接收来自Worker计算的梯度,然后记录到维护的map里
- 对于pull操作,按照key将上一轮更新的weight拿出来返回给Worker
- 具体的优化算法,同步或者异步都可以在这里实现,上述实现的是简单的异步SGD
2.3 Worker 节点
Worker类的构造函数:
LRWorker(const char *train_file,
const char *test_file) :
train_file_path(train_file),
test_file_path(test_file) {
kv_w_ = new ps::KVWorker<float>(0);
base_ = new Base;
core_num = std::thread::hardware_concurrency();
pool_ = new ThreadPool(core_num);
}
此处定义了一个线程池,利用多线程来计算梯度,代码中也包含了线程池的具体实现。
读取数据之后,进行训练:
while (1) {
train_data_loader.load_minibatch_hash_data_fread();
if (train_data->fea_matrix.size() <= 0) break;
int thread_size = train_data->fea_matrix.size() / core_num;
gradient_thread_finish_num = core_num;
for (int i = 0; i < core_num; ++i) {
int start = i * thread_size;
int end = (i + 1)* thread_size;
pool->enqueue(std::bind(&LRWorker::update, this, start, end));
}
while (gradient_thread_finish_num > 0) {
usleep(5);
}
++block;
}
将数据分块,每个线程处理一份数据,调用LRWorker::update函数对参数进行更新
void LRWorker::update(int start, int end) {
size_t idx = 0;
auto all_keys = std::vector<Base::sample_key>();
auto unique_keys = std::vector<ps::Key>();;
int line_num = 0;
for (int row = start; row < end; ++row) {
int sample_size = train_data->fea_matrix[row].size();
Base::sample_key sk;
sk.sid = line_num;
for (int j = 0; j < sample_size; ++j) {
idx = train_data->fea_matrix[row][j].fid;
sk.fid = idx;
all_keys.push_back(sk);
unique_keys.push_back(idx);
}
++line_num;
}
std::sort(all_keys.begin(), all_keys.end(), base_->sort_finder);
std::sort(unique_keys.begin(), unique_keys.end());
unique_keys.erase(unique(unique_keys.begin(), unique_keys.end()),
unique_keys.end());
int keys_size = (unique_keys).size();
auto w = std::vector<float>(keys_size);
auto push_gradient = std::vector<float>(keys_size);
kv_w_->Wait(kv_w_->Pull(unique_keys, &(w)));
auto loss = std::vector<float>(end - start);
calculate_loss(w, all_keys, unique_keys, start, end, loss);
calculate_gradient(all_keys, unique_keys, loss, push_gradient);
kv_w_->Wait(kv_w_->Push(unique_keys, push_gradient));
--gradient_thread_finish_num;
}
这部分是Worker的核心处理逻辑,包含以下几个方面:
- 结合数据组织的Key(ps::Key),去掉没有用到的特征;
- 根据参数对应的Key从Server那里Pull取最新的参数;
- 用最新的参数计算loss和gradient,code较长,感兴趣的可以到github了解
- 计算得到的gradient,然后Push到Server中,进行参数的更新
直到Worker的迭代结束,Server和Scheduler也相继关闭链接,调用ps::Finalize() 进行回收。
简单的分布式LR就这样实现了。
参考
- ^xflow https://github.com/xswang/xflow
|
|



 发表于 2023-4-9 16:43:59
发表于 2023-4-9 16:43:59