|
|
WHAT
什么是流
流是“从支持数据处理操作的源生成的一系列元素”。
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。可以把它们看成遍历数据集的高级迭代器。流还可以透明地并行处理,你无需写任何多线程代码了
WHY
1. 集合操作却远远算不上完美
集合是Java中使用最多的API。几乎每个Java应用程序都会制造和处理集合。集合对于很多编程任务来说都是非常基本的:它们可以让你把数据分组并加以处理。但集合操作却远远算不上完美.
很多业务逻辑都涉及类似于数据库的操作,大部分数据库都允许你声明式地指定这些操作。比如,以下SQL查询语句SELECT name FROM dishes WHERE calorie < 400 。你看,你不需要实现如何根据菜肴的属性进行筛选(比如利用迭代器和累加器),你只需要表达你想要什么。这个基本的思路意味着,你用不着担心怎么去显式地实现这些查询语句——都替你办好了!集合这里就不能这样?
要处理大量元素,为了提高性能,你需要并行处理,并利用多核架构。但写并行代码比用迭代器还要复杂,而且调试起来也够受的!
2. Stream的好处
Java 8中的Stream API可以让你写出这样的代码
- 声明性——更简洁,更易读
- 可复合——更灵活
- 可并行——性能更好
Streams库的内部迭代可以自动选择一种适合你硬件的数据表示和并行实现。 HOW
简介
Java 8中的集合支持一个新的stream 方法,它会返回一个流 。
java.util.stream.Stream 概念
从支持数据处理操作的源生成的元素序列
元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如 ArrayList 与 LinkedList )。但流的目的在于表达计算,比如你前面见到的filter 、 sorted 和 map 。集合讲的是数据,流讲的是计算。
源——流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如 filter 、 map 、 reduce 、 find 、 match 、 sort 等。流操作可以顺序执行,也可并行执行。
流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。流水线的操作可以看作对数据源进行数据库式查询。
内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
流与集合
概念区别
Java现有的集合概念和新的流概念都提供了接口,来配合代表元素型有序值的数据接口。所谓有序,就是说我们一般是按顺序取用值,而不是随机取用的。
集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。
流则是在概念上固定的数据结构,其元素则是按需计算的。这是一种生产者-消费者的关系。从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值(用管理学的话说这就是需求驱动,甚至是实时制造)。 流的特点
集合和流的另一个关键区别在于它们遍历数据的方式。
- 1.只能遍历一次
流只能遍历一次。遍历完之后,这个流已经被消费掉。
以下代码会抛出一个异常,说流已被消费掉
List<String> title = Arrays.asList(&#34;Java8&#34;, &#34;In&#34;, &#34;Action&#34;);
Stream<String> s = title.stream();
s.forEach(System.out::println);
s.forEach(System.out::println);
//java.lang.IllegalStateException:流已被操作或关闭- 2.外部迭代与内部迭代
使用 Collection 接口需要用户去做迭代(比如用 for-each ),这称为外部迭代。 相反,Streams库使用内部迭代——内部把迭代做了,还把得到的流值存在了某个地方,你只要给出一个函数说要干什么就可以了。迭代通过 filter 、 map 、 sorted 等操作被抽象掉了 //外部迭代
List<String> names = new ArrayList<>();
Iterator<String> iterator = menu.iterator();
while(iterator.hasNext()) {
Dish d = iterator.next();
names.add(d.getName());
}
//内部迭代
List<String> names = menu.stream()
.map(Dish::getName)
.collect(toList());
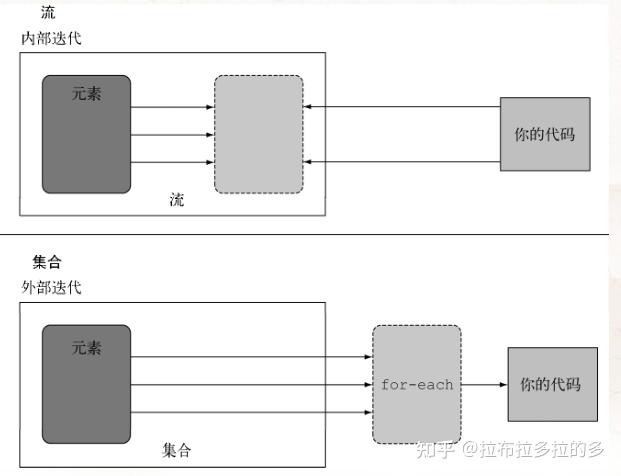
内部迭代与外部迭代
流的操作
连接起来的流操作称为中间操作,关闭流的操作称为终端操作
java.util.stream.Stream 中的 Stream 接口定义了许多操作。
可以分为两大类:
- filter 、 map 和 limit 可以连成一条流水线;
- collect 触发流水线执行并关闭它;
List<String> names = menu.stream() //从菜单获得流
.filter(d -> d.getCalories() > 300).map(Dish::getName).limit(3) //中间操作 filter 、 map 和 limit可以连成一条流水
.collect(toList()); //将 Stream 转换为 List collect 触发流水线执行并关闭它
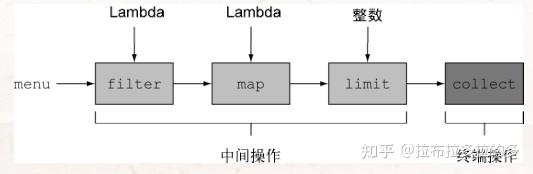
中间操作与终端操作
- 1.中间操作
中间操作会返回另一个流,让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理。 短路的技巧
循环合并:尽管 filter 和 map 是两个独立的操作,但它们合并到同一次遍历中了
- 2.终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如 List 、 Integer ,甚至 void 。 使用流
流的流水线背后的理念类似于构建器模式.
在构建器模式中有一个调用链用来设置一套配置(对流来说这就是一个中间操作链)
,接着是调用 built 方法(对流来说就是终端操作)
XXXEntity.builder().createTime(createTime).build();流的使用一般包括三件事
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果
关键词
筛选、切片和匹配 查找、匹配和归约 使用数值范围等数值流 多个源创建流 无限流
筛选和切片
用谓词筛选,选择流中的元素,筛选出各不相同的元素,忽略流中的头几个元素,或将流截短至指定长度。
- filter
- distinct
- limit 截短流
- skip(n) 跳过元素 limit(n) 和 skip(n) 互补
// filter 方法 方法引用检查菜肴是否适合素食者
List<Dish> vegetarianMenu = menu.stream().filter(Dish::isVegetarian).collect(toList());
// distinct 返回一个元素各异(根据流所生成元素的hashCode 和 equals 方法实现)的流
//筛选出列表中所有的偶数,并确保没有重复
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream().filter(i -> i % 2 == 0).distinct()
.forEach(System.out::println);
//limit(n) 方法,该方法会返回一个不超过给定长度的流。
//limit 也可以用在无序流上,比如源是一个 Set 。这种情况下, limit 的结果不会以任何顺序排列。
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300).limit(3)
.collect(toList());
// skip(n) 返回一个扔掉了前 n 个元素的流如果流中元素不足 n 个,则返回一个空流。 limit(n) 和 skip(n) 是互补的!
limit 也可以用在无序流上,比如源是一个 Set 。这种情况下, limit 的结果不会以任何顺序排列 映射
Stream API也通过 map 和 flatMap 方法从某些对象中选择信息.
- [1]map 方法
对流中每一个元素应用函数,并将其映射成一个新的元素,它是“创建一个新版本”而不是去“修改”
- [2] flatMap 流的扁平化
map(Arrays::stream) 时生成的单个流都被合并起来,扁平化为一个流,flatmap 方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
//把方法引用 Dish::getName 传给了 map 方法,来提取流中菜肴的名称
// getName 方法返回一个 String ,所以 map 方法输出的流的类型就是 Stream<String>
List<String> dishNames = menu.stream().map(Dish::getName)
.collect(toList());
List<Integer> dishNameLengths = menu.stream()
.map(Dish::getName).map(String::length)
.collect(toList());
//对于一张单词 表 , 如 何 返 回 一 张 列 表 , 列 出 里 面 各 不 相 同 的 字 符
//使用 flatMap 各个数组并不是分别映射成一个流,而是映射成流的内容.
List<String> uniqueCharacters =
words.stream().map(w -> w.split(&#34;&#34;)) //将每个单词转换为由其字母构成的数组
.flatMap(Arrays::stream) //将各个生成流扁平化为单个流
.distinct()
.collect(Collectors.toList());- [3] 查找和匹配
匹配 StreamAPI通过 allMatch 、 anyMatch 、 noneMatch 、 findFirst 和 findAny 方法.
- 否至少匹配一个元素 anyMatch
- 是否匹配所有元素 allMatch
- 没有任何元素匹配 noneMatch
if(menu.stream().anyMatch(Dish::isVegetarian)){
System.out.println(&#34;The menu is (somewhat) vegetarian friendly!!&#34;);
}
boolean isHealthy = menu.stream().allMatch(d -> d.getCalories() < 1000);
boolean isHealthy = menu.stream().noneMatch(d -> d.getCalories() >= 1000);查找元素
流水线将在后台进行优化使其只需走一遍,并在利用短路找到结果时立即结束。
何时使用 findFirst 和 findAny?
你可能会想,为什么会同时有 findFirst 和 findAny 呢?答案是并行。找到第一个元素在并行上限制更多。如果你不关心返回的元素是哪个,请使用 findAny ,因为它在使用并行流时限制较少。
- [3] 归约
归约操作: 可以理解为计算相关的操作,求和 最大值和最小值
//元素求和 一个初始值,
//这里是0 一个 BinaryOperator<T> 来将两个元素结合起来产生一个新值
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
int sum = numbers.stream().reduce(0, Integer::sum);
//不接受初始值,但是会返回一个 Optional 对象
Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b));
//(x, y) -> x < y ? x : y
Optional<Integer> max = numbers.stream().reduce(Integer::max);
Optional<Integer> min = numbers.stream().reduce(Integer::min);
//内置 count 方法可用来计算流中元素的个数
long count = menu.stream().count();map 和 reduce 的连接通常称为 map-reduce 模式
long count = menu.stream().count(); 实践
@Data////
@AllArgsConstructor
public class Trader{
private final String name;
private final String city;
}
@Data
@AllArgsConstructor
public class Transaction{
private final Trader trader;
private final int year;
private final int value;
public static void main(String ...args){
Trader raoul = new Trader(&#34;Raoul&#34;, &#34;Cambridge&#34;);
Trader mario = new Trader(&#34;Mario&#34;,&#34;Milan&#34;);
Trader alan = new Trader(&#34;Alan&#34;,&#34;Cambridge&#34;);
Trader brian = new Trader(&#34;Brian&#34;,&#34;Cambridge&#34;);
List<Transaction> transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
//找出2011年的所有交易并按交易额排序(从低到高)
List<Transaction> tr2011 =
transactions.stream()
.filter(transaction -> transaction.getYear() == 2011) //给 filter 传递一个谓词来选择2011年的交易
.sorted(comparing(Transaction::getValue)) //按照交易额进行排序
.collect(toList()); //将生成的 Stream 中的所有元素收集到一个 List 中
//交易员都在哪些不同的城市工作过
List<String> cities = transactions.stream()
.map(transaction -> transaction.getTrader().getCity()) //提取与交易相关的每位交易员的所在城市
.distinct() //只选择互不相同的城市
.collect(toList());
Set<String> cities = transactions.stream()
.map(transaction -> transaction.getTrader().getCity())
.collect(toSet());
//查找所有来自于剑桥的交易员,并按姓名排序
List<Trader> traders = transactions.stream()
.map(Transaction::getTrader)
.filter(trader -> trader.getCity().equals(&#34;Cambridge&#34;))
.distinct() //确保没有任何重复
.sorted(comparing(Trader::getName))
.collect(toList());
//返回所有交易员的姓名字符串,按字母顺序排序
Sring traderStr =
transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted()
.reduce(&#34;&#34;, (n1, n2) -> n1 + n2); //逐个拼接每个名字,得到一个将所有名字连接起来的 String
//此解决方案效率不高(所有字符串都被反复连接,每次迭代的时候都要建立一个新的 String 对象)
String traderStr =transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted()
.collect(joining());
//有没有交易员是在米兰工作的
boolean milanBased = transactions.stream()
.anyMatch(transaction -> transaction.getTrader() .getCity().equals(&#34;Milan&#34;));
//把一个谓词传递给 anyMatch ,检查是否有交易员在米兰工作
//打印生活在剑桥的交易员的所有交易额
transactions.stream()
.filter(t -> &#34;Cambridge&#34;.equals(t.getTrader().getCity()))
.map(Transaction::getValue)
.forEach(System.out::println);
//所有交易中,最高的交易额是多少
Optional<Integer> highestValue = transactions.stream()
.map(Transaction::getValue)
.reduce(Integer::max);
//找到交易额最小的交易
Optional<Transaction> smallestTransaction =transactions.stream()
.reduce((t1, t2) ->t1.getValue() < t2.getValue() ? t1 : t2); //通过反复比较每个交易的交易额,找出最小的交易
//流支持 min 和 max 方法,它们可以接受一个 Comparator 作为参数,指定计算最小或最大值时要比较哪个键值
Optional<Transaction> smallestTransaction =
transactions.stream().min(comparing(Transaction::getValue));
} 数值流
int calories = menu.stream().map(Dish::getCalories).reduce(0, Integer::sum); 这段问题是,它有一个暗含的装箱成本。每个 Integer 都必须拆箱成一个原始类型,再进行求和
1 原始类型流特化
Java 8引入了三个原始类型特化流接口来解决装箱拆箱问题, IntStream 、 DoubleStream 和LongStream ,分别将流中的元素特化为 int 、 long 和 double ,从而避免了暗含的装箱成本。
每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的 sum ,找到最大元素的 max 。此外还有在必要时再把它们转换回对象流的方法。这些特化的原因并不在于流的复杂性,而是装箱造成的复杂性——即类似 int 和 Integer 之间的效率差异。
常用方法是 mapToInt 、 mapToDouble 和 mapToLong ,只是它们返回的是一个特化流,而不是Stream<T>
int calories = menu.stream()
.mapToInt(Dish::getCalories) //返回一个IntStream
.sum();
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
Stream<Integer> stream = intStream.boxed();
Optional 可以用Integer 、 String 等参考类型来参数化
三种原始流特化,也分别有一个 Optional 原始类型特化版本: OptionalInt 、 OptionalDouble 和 OptionalLong 。
OptionalInt maxCalories = menu.stream().mapToInt(Dish::getCalories).max();
int max = maxCalories.orElse(1); //如果没有最大值的话,显式提供一个默认最大值
2 数值范围
Java 8引入了两个可以用于 IntStream 和 LongStream 的静态方法,帮助生成这种范围:range 和 rangeClosed 。这两个方法都是第一个参数接受起始值,第二个参数接受结束值。
range 是不包含结束值的,而 rangeClosed 则包含结束值.
//表 示 范 围[1, 100]
IntStream evenNumbers = IntStream.rangeClosed(1, 100)
.filter(n -> n % 2 == 0); //一个从1到100的偶数流
System.out.println(evenNumbers.count()); //从1到100有50个偶数-- 数值流应用
勾股数
//三元组
stream.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
IntStream.rangeClosed(1, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.boxed()
.map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
IntStream.rangeClosed(1, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.mapToObj(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
//生成值
Stream<int[]> pythagoreanTriples = IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.mapToObj(b ->
new int[]{a, b, (int)Math.sqrt(a * a + b * b)}));
pythagoreanTriples.limit(5)
.forEach(t ->
System.out.println(t[0] + &#34;, &#34; + t[1] + &#34;, &#34; + t[2]));
//最终版本
Stream<double[]> pythagoreanTriples2 =
IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.mapToObj(
b -> new double[]{a, b, Math.sqrt(a*a + b*b)})
.filter(t -> t[2] % 1 == 0));构建流
1 由值创建流 Stream.of
Stream<String> stream = Stream.of(&#34;Java 8 &#34;, &#34;Lambdas &#34;, &#34;In &#34;, &#34;Action&#34;);
stream.map(String::toUpperCase).forEach(System.out::println);
//你可以使用 empty 得到一个空流,如下所示:
Stream<String> emptyStream = Stream.empty();2 由数组创建流
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();3 由文件生成流
Java中用于处理文件等I/O操作的NIO API(非阻塞 I/O)已更新,以便利用Stream API。java.nio.file.Files 中的很多静态方法都会返回一个流 long uniqueWords = 0;
try(Stream<String> lines =
Files.lines(Paths.get(&#34;data.txt&#34;), Charset.defaultCharset())){
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(&#34; &#34;)))
.distinct() //删除重复项
.count(); //数一数有多少各不相同的单词
}
catch(IOException e){ } //如果打开文件时出现异常则加以处理
4 由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流: Stream.iterate 和 Stream.generate 。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由 iterate和 generate 产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!一般来说,应该使用 limit(n) 来对这种流加以限制,以避免打印无穷多个值。
在需要依次生成一系列值的时候应该使用 iterate //1. 迭代 这种 iterate 操作基本上是顺序的,因为结果取决于前一次应用
//这里只选择了前10个偶数。然后可以调用 forEach 终端操作来消费流,并分别打印每个元素。
Stream.iterate(0, n -> n + 2)
.limit(10)
.forEach(System.out::println);
//iterate 方法接受一个初始值(在这里是 0 ),还有一个依次应用在每个产生的新值上的
//Lambda( UnaryOperator<t> 类型)。这里,我们使用Lambda n -> n + 2 ,返回的是前一个元
//素加上2
//斐波纳契元组序列
/* 斐波纳契数列是著名的经典编程练习。下面这个数列就是斐波纳契数列的一部分:0, 1, 1,
2, 3, 5, 8, 13, 21, 34, 55…数列中开始的两个数字是0和1,后续的每个数字都是前两个数字之和。
斐波纳契元组序列与此类似,是数列中数字和其后续数字组成的元组构成的序列:(0, 1),
(1, 1), (1, 2), (2, 3), (3, 5), (5, 8), (8, 13), (13, 21) …
你的任务是用 iterate 方法生成斐波纳契元组序列中的前20个元素。*/
Stream.iterate(new int[]{0, 1}, ???)
.limit(20)
.forEach(t -> System.out.println(&#34;(&#34; + t[0] + &#34;,&#34; + t[1] +&#34;)&#34;));
//2. 生成
//generate 方法也可让你按需生成一个无限流。但 generate 不是依次
//对每个新生成的值应用函数的。它接受一个 Supplier<T> 类型的Lambda提供新的值。
Stream.generate(Math::random)
.limit(5)
.forEach(System.out::println);
// IntStream 的 generate 方
//法会接受一个 IntSupplier ,而不是 Supplier<t> 。
//使用 IntStream 说明避免装箱操作的代码
IntStream ones = IntStream.generate(() -> 1);
//斐波纳契项的IntSupplier
IntSupplier fib = new IntSupplier(){
private int previous = 0;
private int current = 1;
public int getAsInt(){
int oldPrevious = this.previous;
int nextValue = this.previous + this.current;
this.previous = this.current;
this.current = nextValue;
return oldPrevious;
}
};
IntStream.generate(fib).limit(10).forEach(System.out::println);在并行代码中使用有状态的供应源是不安全的
其他要点
[1] 归约方法的优势与并行化
使用 reduce 的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行 reduce 操作。而迭代式求和例子要更新共享变量 sum ,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升!这种计算的并行化需要另一种办法:将输入分块,分块求和,最后再合并起来。
[2] 流操作:无状态和有状态
诸如 map 或 filter 等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。这些操作一般都是 无状态的:它们没有内部状态(假设用户提供的Lambda或方法引用没有内部可变状态)
但诸如 reduce 、 sum 、 max 等操作需要内部状态来累积结果。在上面的情况下,内部状态很小。管流中有多少元素要处理,内部状态都是有界的.
诸如 sort 或 distinct 等操作一开始都和 filter 和 map 差不多——都是接受一个流,再生成一个流(中间操作),但有一个关键的区别。从流中排序和删除重复项时都需要知道先前的历史。这些操作叫作 有状态操作
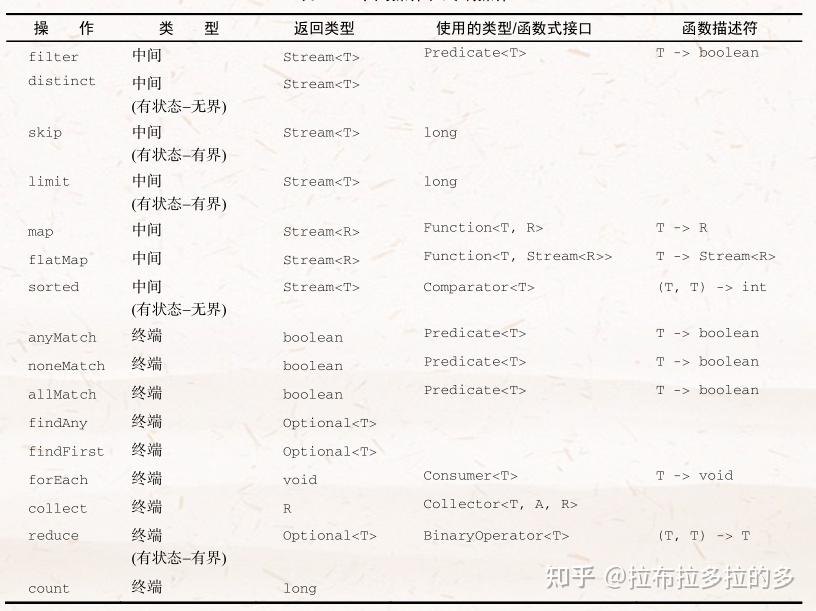
中间操作和终端操作 的状态
[3] Optional 简介
Optional<T> 类( java.util.Optional )是一个容器类,代表一个值存在或不存在。在上面的代码中, findAny 可能什么元素都没找到。Java 8的库设计人员引入了 Optional<T> ,这样就不用返回众所周知容易出问题的 null 了。
isPresent() 将在 Optional 包含值的时候返回 true , 否则返回 false 。
ifPresent(Consumer<T> block) 会在值存在的时候执行给定的代码块。
T get() 会在值存在时返回值,否则抛出一个 NoSuchElement 异常。
T orElse(T other) 会在值存在时返回值,否则返回一个默认值。
menu.stream()
.filter(Dish::isVegetarian)
.findAny()
.ifPresent(d -> System.out.println(d.getName()); |
|



 发表于 2023-3-25 14:51:27
发表于 2023-3-25 14:51:27