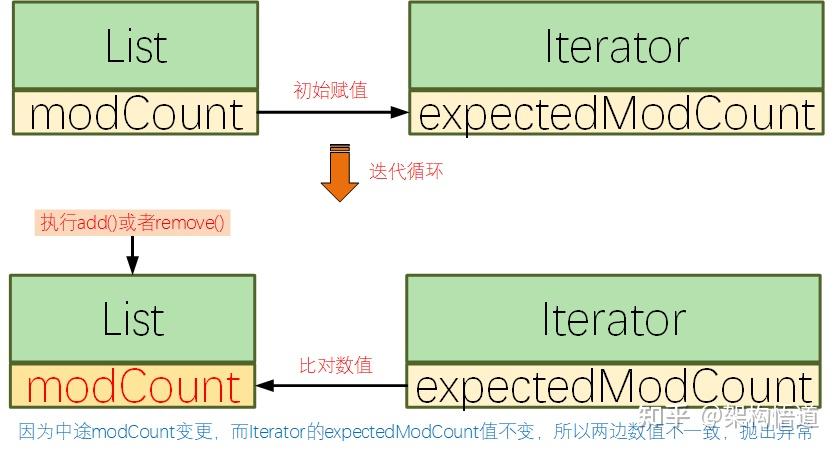
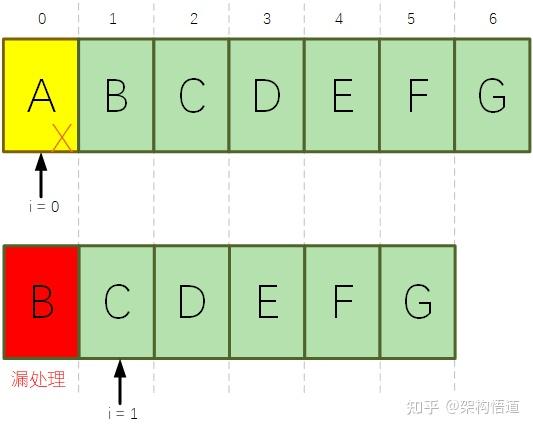
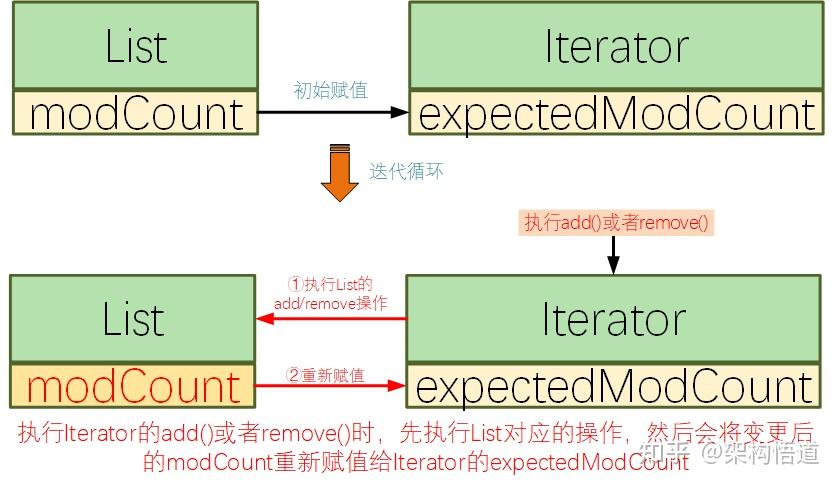
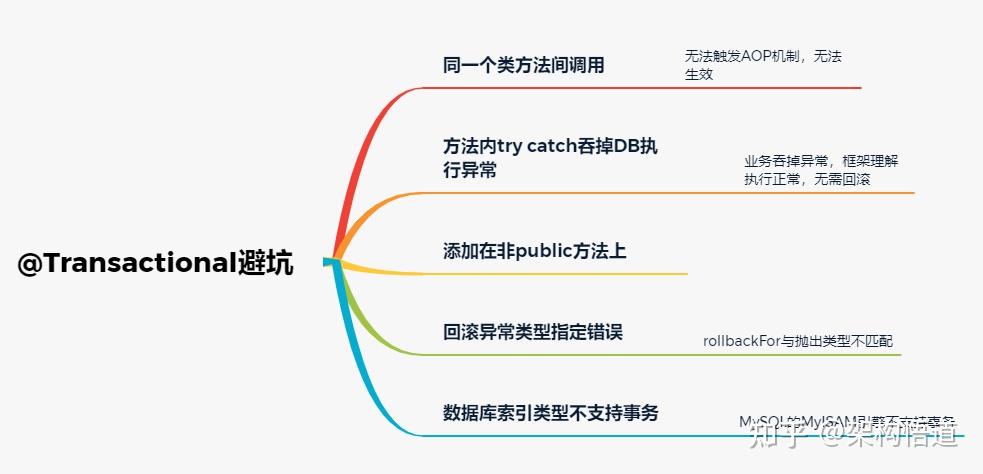
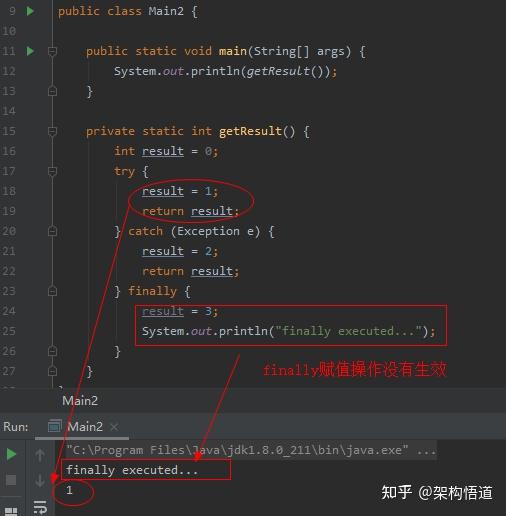
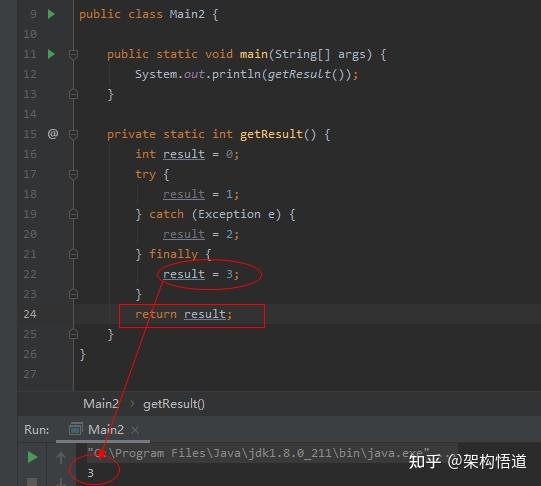
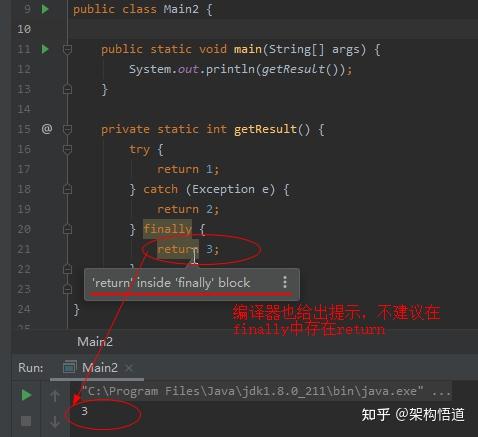
遍历List然后对list中符合条件的元素进行删除操作,这是项目里面非常常见的一个场景。
先看下两种典型的错误写法: 错误写法1:
for (User user : userList) {
if ("男".equals(user.getSex())) {
userList.remove(user);
}
}
错误写法2:
for (int i = 0; i < userList.size(); i++>) {
if (&#34;男&#34;.equals(user.getSex())) {
userList.remove(i);
}
} 错误原因:
删除元素之后,元素下标发生前移,但是指针是不变的,再处理下一个的时候,就可能会有部分元素被漏掉没有处理。
那正确的方式应该如何处理呢?接着往下看。 正确写法1:
// 使用迭代器来实现
Iterator iterator = userList.iterator();
while (iterator.hasNext()) {
if (&#34;男&#34;.equals(user.getSex())) {
iterator.remove();
}
}
参考下redis之类的依赖内存的缓存中间件,都有一个绕不开的兜底策略,即数据淘汰机制。对于业务类编码实现的时候,如果使用Map等容器类来实现全局缓存的时候,应该要结合实际部署情况,确定内存中允许的最大数据条数,并提供超出指定容量时的处理策略。比如我们可以基于LinkedHashMap来定制一个基于LRU策略的缓存Map,来保证内存数据量不会无限制增长。
public class FixedLengthLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;



 发表于 2023-1-18 08:14:08
发表于 2023-1-18 08:14:08